
In Part 1, we've covered a flaw in the Superchain upgrade mechanism that could lead to double withdrawals on L1. Today, we'll take a step back from Solidity and dive into a consensus bug in the OP-node reference client. For our work and responsible disclosure, OP generously awarded us a $7.5k USDC bounty.
The Block Derivation Process
Every rollup must have a method to fully derive the L2 state up to some safe block, purely by observing commitments sent on L1. In the OP stack, this is a highly complex process defined in this specification. Days and nights have been spent perfecting and accounting for edge cases, so that at any point, every client will have the exact same view of the L2.
At it's core, the information of the L2 is simply what happened at each block. The data is encoded in a structure referred to as batch, described here. A second batch format came out in Delta upgrade, to support better compression. It includes description of many different blocks in a single structure.
Many batch structures are concatenated together and then RLP-encoded (standard Ethereum encoder). What you need to know about this encoding is that there are only two item types - Strings and Lists, where Strings do not expand to further items while Lists contain possibly more Lists or Strings. The result goes through a Zlib compressor and is now called a "channel". This is a sort of mid-way point between the transport-layer representation and the derivation-layer data. A channel can be broken down to different frames (each with a sequential frame ID and a channel ID), and those are directly sent as L1 calldata.
The channel and batch formats are the only relevant ones for the purposes of our issue. Let's trace how a new channel is consumed by the derivation pipeline.
A short code dive
At the code level, the different parsing stages are part of a sequence of pipeline items, they are listed in pipeline.go:

The pipeline is executed from the end to the beginning, i.e. attributesQueue will request the next data from attributesBuilder, which will request from batchQueue, and so on, until the l1Traversal which will actually get the content from L1. Here is how the channel reader fetches the next batch for the batch queue:
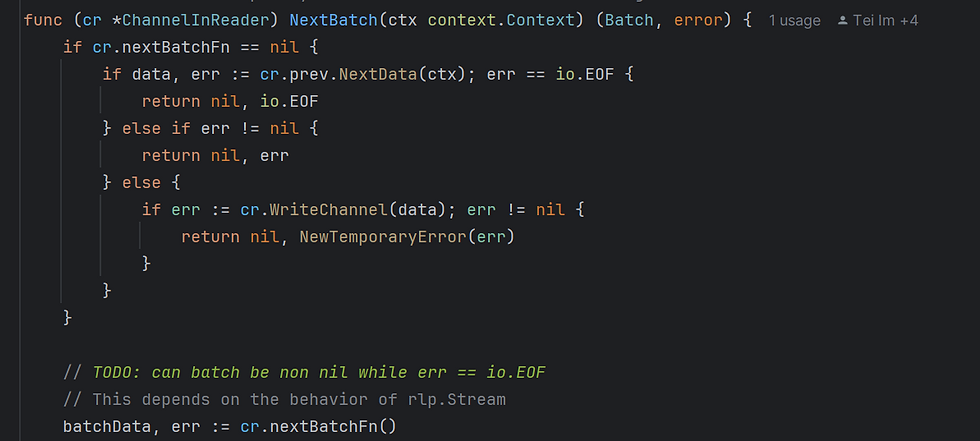
At the beginning, nextBatchFn is empty, so it will request NextData() from the frame bank (the previous pipeline stage). It will then call WriteChannel() to prepare nextBatchFn. After making sure the function pointer is available, it is called with cr.nextBatchFn().

The engineering here is a little involved, but essentially the nextBatch function to run is gotten dynamically from running BatchReader. The call handles the compression layer (Zlib or Brotli), and returns a function which decodes the next encoded batch from the RLP stream. The function is called repeatedly from the channel reader until no more batches are left to read.
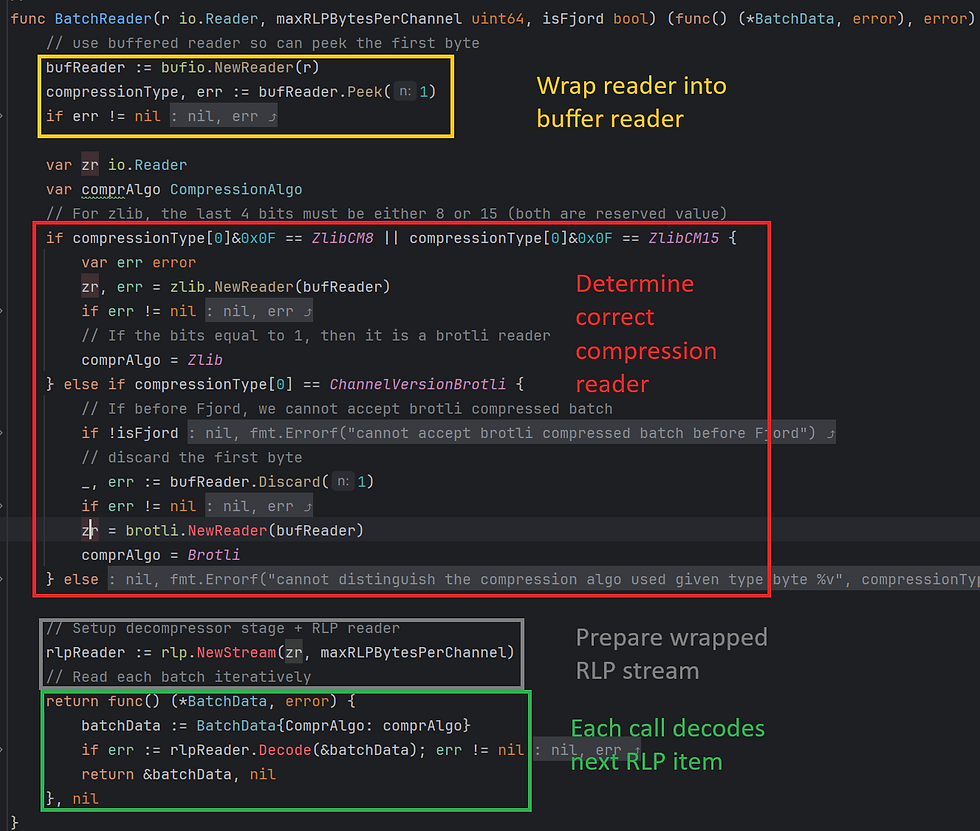
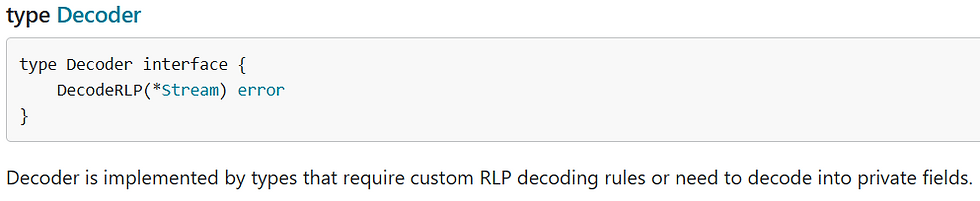
Now, since batchData is a custom data type, it can implement EncodeRLP()/DecodeRLP() to handle the data fields. From the rlp docs:
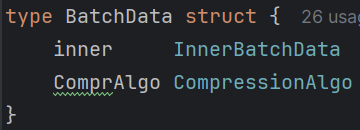
The BatchData structure is a tiny wrapper on the InnerBatchData. That's because as mentioned, there are two supported batch formats.
The custom decoder reads the next RLP string using Bytes(), then sends it to decodeTyped()
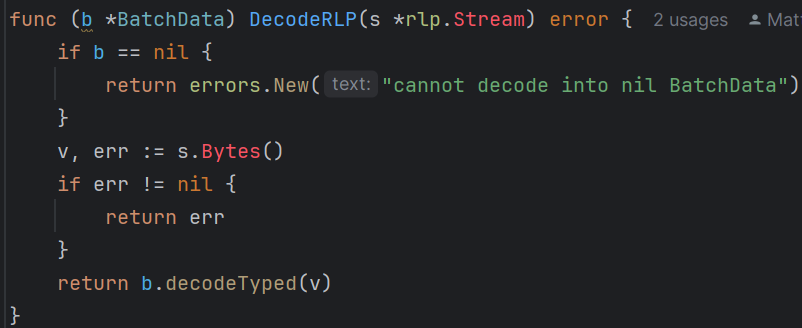
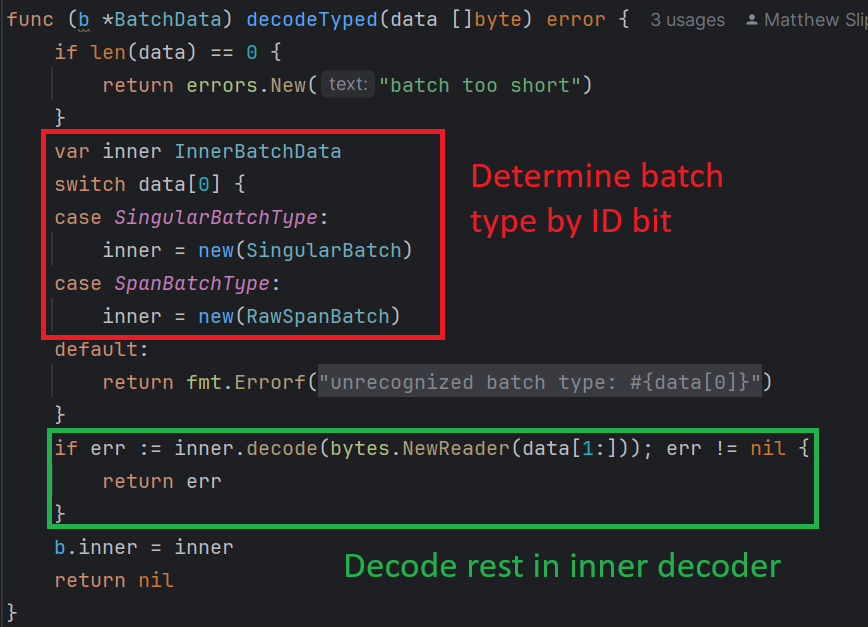
It would be enough for our purposes to just look at the SingularBatch, the simpler of the two types.
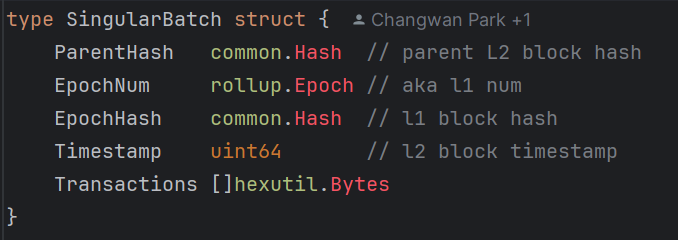
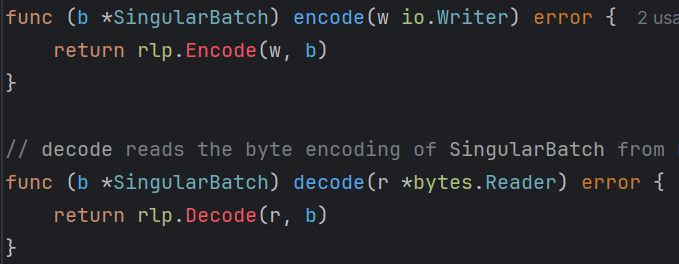
The decode() function uses default rlp library decoding rules to unwrap the incoming bytes to the target structure. No further custom decoding is necessary - a Hash or Epoch are aliased to primitive types. Note that this means there are two RLP encoding layers - one at the channel level, another at the inner batch data level.
To decode into a struct, decoding expects the input to be an RLP list. The decoded elements of the list are assigned to each public field in the order given by the struct's definition. The input list must contain an element for each decoded field. Decoding returns an error if there are too few or too many elements for the struct.
So, our decoding crash course shows the code path from a received completed channel, to a complete BatchData the channel reader can happily return for the BatchQueue for processing. What could go wrong?
The Issue
The specification makes it very clear what the expected batch format looks like. This coincides with the Go structure above:

As said - malformed contents must be ignored by the rollup node. The rlp decoding will indeed revert if the incoming bytes cannot be treated as a Batch. For example if the byte stream ends before providing a TX list, or has another variable after it, or timestamp bit size is too large, it will raise an error which will cause the batch to be ignored.
However, there is one thing rlp.Decode() does not check, because it's not its purpose. The function reads the next RLP item as a Batch, but it may not be the last item. Consider the following RLP stream:
RLP List
RLP String - ParentHash
RLP String - EpochNum
RLP String - EpochHash
RLP String -Timestamp
RLP List - TXList
RLP String - TX 1
RLP String - TX 2
RLP List
RLP String Garbage1
RLP String Garbage2
...
Clearly, this stream can be considered malformed, as it is not, by definition:
rlp_encode([parent_hash, epoch_number, epoch_hash, timestamp, transaction_list]) |
It is rather:
rlp_encode([parent_hash, epoch_number, epoch_hash, timestamp, transaction_list], [Garbage1, Garbage2]) |
So, the expected behavior would be to ignore the batch.
Impact
OP node would not derive correctly whenever a Batch has trailing RLP items. Deriving invalid blocks is more dangerous than not deriving valid ones, because a user can exploit it easily (e.g. by convincing a victim that a payment has gone through, etc). While the impact is critical per the BBP, likelihood brings down the overall severity:
Batch data is read from a highly trusted source (for now), that is unlikely to produce malformed data.
There are very few other OP consensus nodes (for now)
It should be mentioned that the considerations above are mainly due to the OP stack being relatively early in its lifetime. It is possible that the batcher role would be decentralized in the future, and other nodes are being developed at this very moment. It's critical that gaps are found (and reported) early on, to minimize the impact on the ecosystem.
Bounty & Resolution
The issue was reported by private channels to Optimism, which confirmed the issue within few days. They have offered a bounty of $7.5k USDC, which we find to be very reasonable after making all the considerations.
The team opted to fix the issue by changing the specs, and highlighting that trailing garbage, in this case, should be accepted. It is early enough in OP lifetime that this is a reasonable step.
Note if the batch version and contents can be RLP decoded correctly but extra content exists beyond the batch, the additional data may be ignored during parsing. Data between RLP encoded batches may not be ignored (as they are seen as malformed batches), but if a batch can be fully described by the RLP decoding, extra content does not invalidate the decoded batch.
Key Takeaways
Decoding logic in consensus clients is a very underappreciated attack surface.
Carefully read documentation of third-party libraries
Consider language-level biases. The way rlp.Decode() integrates natively with Golang types was a footgun in this instance, making developers forget that other data may follow.
Hope you enjoyed dissecting this bug together! Stay tuned for more OP-related bugs and content in Part 3.
About TrustSec
TrustSec is a world-renowned boutique auditing and bug bounty firm, founded by famed white-hat hacker Trust in 2022. Since then, we have published over 100 reports for a wide range of clients and received bug bounties from more than 40 projects. Composed exclusively of top competitive bounty hunters, TrustSec employs unique, fully collaborative methodologies to secure even the most complex codebases. Visit our website to learn why top names like Optimism, zkSync, OlympusDAO, The Graph, BadgerDAO, Reserve Protocol, and many others trust us as their security partner.
Comments